Risk-First Analysis Framework
Start Here
Home
Contributing
Quick Summary
A Simple Scenario
The Risk Landscape
Discuss
Please star this project in GitHub to be invited to join the Risk First Organisation.
Publications

Click Here For Details
Complexity Risk
Complexity Risks are the risks to your project due to its underlying “complexity”. This section will break down exactly what we mean by complexity, and where it can hide on a software project, and look at some ways in which we can manage this important risk.
Codebase Risk
We’re going to start by looking at code you write: the size of your code-base, the amount of code, the number of modules, the interconnectedness of the modules and how well-factored the code is.
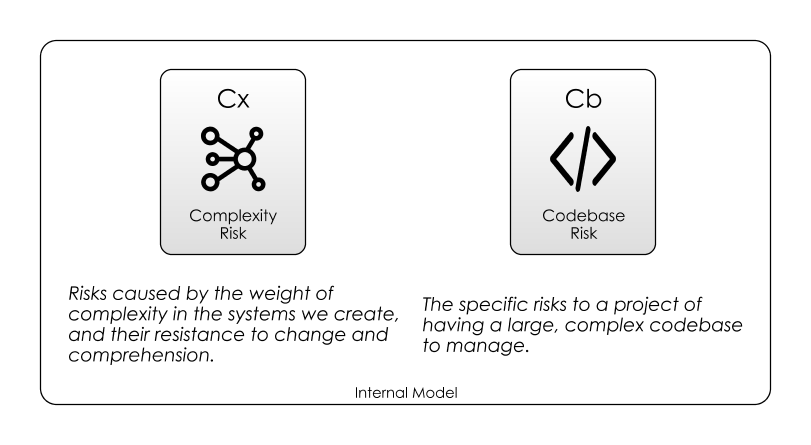
You could think of this as Codebase Risk, being a specific type of Complexity Risk. We’ll look at two measures of codebase complexity before talking about Technical Debt and Feature Creep.
Kolmogorov Complexity
The standard Computer-Science definition of complexity, is Kolmogorov Complexity. This is:
“…the length of the shortest computer program (in a predetermined programming language) that produces the object as output.” - Kolmogorov Complexity, Wikipedia
This is a fairly handy definition for us, as it means that in writing software to solve a problem, there is a lower bound on the size of the software we write. While in practice this is pretty much impossible to quantify, that doesn’t really matter: here I want to focus on the techniques for moving towards that minimum.
Let’s say we wanted to write a JavaScript program to output this string:
abcdabcdabcdabcdabcdabcdabcdabcdabcdabcd
We might choose this representation:
function out() { (7 )
return "abcdabcdabcdabcdabcdabcdabcdabcdabcdabcd" (45)
} (1 )
The numbers in brackets indicate how many symbols each line contains, so in total, this code block contains 53 symbols, if you count function, out and return as one symbol each.
But, if we write it like this:
const ABCD="ABCD"; (11)
function out() { (7 )
return ABCD+ABCD+ABCD+ABCD+ABCD+ABCD+ABCD+ (16)
ABCD+ABCD+ABCD; (6 )
} (1 )
With this version, we now have 41 symbols (ABCD is a single symbol - it’s just a name). And with this version:
const ABCD="ABCD"; (11)
function out() { (7 )
return ABCD.repeat(10) (7 )
} (1 )
… we have 26 symbols.
Abstraction
What’s happening here is that we’re exploiting a pattern: we noticed that ABCD occurs several times, so we defined it a single time and then used it over and over, like a stamp. This is called abstraction.
By applying abstraction, we can improve in the direction of the Kolmogorov limit. And, by allowing ourselves to say that symbols (like out and ABCD) are worth one complexity point, we’ve allowed that we can be descriptive in naming function and const. Naming things is an important part of abstraction, because to use something, you have to be able to refer to it.
Trade-Off
Generally, the more complex a piece of software is, the more difficulty users will have understanding it, and the more work developers will have changing it. We should prefer the third version of our code over either the first or second because of its brevity.
But we could go further down into Code Golf territory. This javascript program plays FizzBuzz up to 100, but is less readable than you might hope:
for(i=0;i<100;)document.write(((++i%3?'':'Fizz')+
(i%5?'':'Buzz')||i)+"<br>") (62)
So there is at some point a trade-off to be made between Complexity Risk and Communication Risk. That is, after a certain point, reducing Kolmogorov Complexity further risks making the program less intelligible.
Connectivity
A second, useful measure of complexity comes from graph theory, and that is the connectivity of a graph:
“…the minimum number of elements (nodes or edges) that need to be removed to disconnect the remaining nodes from each other” - Connectivity, Wikipedia
To see this in action, have a look at the below graph:
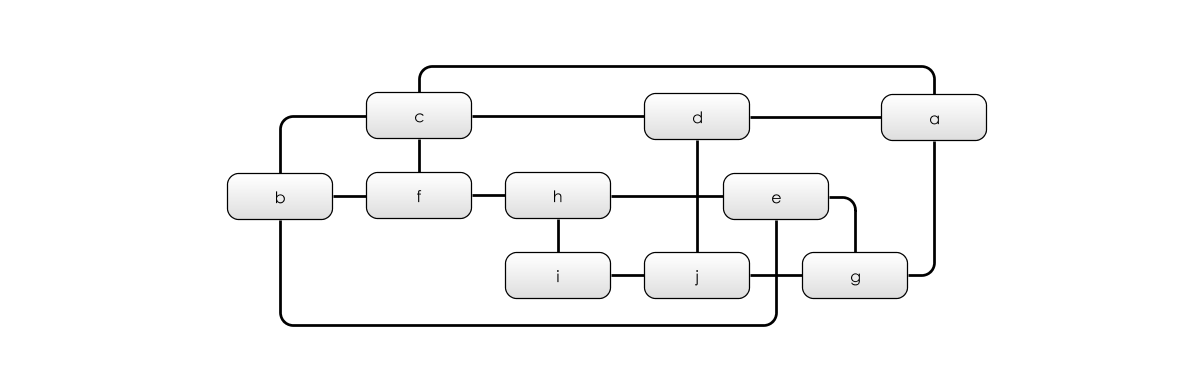
It has 10 vertices, labelled a to j, and it has 15 edges (or links) connecting the vertices together. If any single edge were removed from the diagram above, the 10 vertices would still be linked together. Because of this, we can say that the graph is 2-connected. That is, to disconnect any single vertex, you’d have to remove at least two edges.
As a slight aside, let’s consider the Kolmogorov Complexity of this graph, by inventing a mini-language to describe graphs. It could look something like this:
<item> : [<item>,]* <item> # Indicates that the item
# before the colon
# has a connection to all
# the items after the colon
So our graph could be defined like this:
a: b,c,d
b: c,f,e
c: f,d
d: j
e: h,j
f: h
g: j
h: i
i: j
(39)
Let’s remove some of those extra links:
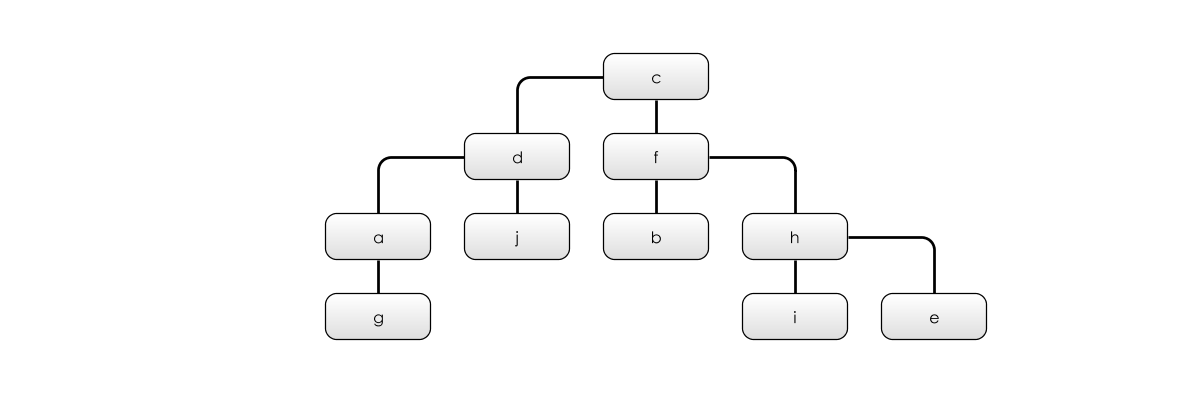
In this graph, I’ve removed 6 of the edges. Now, we’re in a situation where if any single edge is removed, the graph becomes unconnected. That is, it’s broken into distinct chunks. So, it is 1-connected.
The second graph is clearly simpler than the first. And, we can show this by looking at the Kolmogorov Complexity in our little language:
a: d,g
b: f
c: d,f
d: j
f: h
e: h
h: i
(25)
For defining our graphs, Connectivity is also Complexity. And this carries over into software too: heavily connected code is more complex than less-connected code. It’s also harder to reason about and work with because changing one module potentially impacts many others. Let’s dig into this further.
Hierarchies and Modularisation
In the second, simplified graph, I’ve arranged it as a hierarchy, which I can do now that it’s only 1-connected. For 10 vertices, we need 9 edges to connect everything up. It’s always:
edges = vertices - 1
Note that I could pick any hierarchy here: I don’t have to start at c (although it has the nice property that it has two roughly even sub-trees attached to it).
How does this help us? Imagine if a - j were modules of a software system, and the edges of the graph showed communications between the different sub-systems. In the first graph, we’re in a worse position:
- Who’s in charge? What deals with what?
- Can I isolate a component and change it safely?
- What happens if one component disappears?
But, in the second graph, it’s easier to reason about, because of the reduced number of connections and the new hierarchy of organisation.
On the down-side, perhaps our messages have farther to go now: in the original, i could send a message straight to j, but now we have to go all the way via c. But this is the basis of Modularisation and Hierarchy.
As a tool to battle complexity, we don’t just see this in software, but everywhere in our lives. Society, business, and living organisms. For example in our bodies we have:
- Organelles - such as Mitochondria, contained in…
- Cells - such as blood cells, nerve cells, skin cells in the Human Body, inside…
- Organs - like hearts livers, brains etc, held within…
- Organisms - like you and me.
The great complexity-reducing mechanism of modularisation is that you only have to consider your local environment.
So, we’ve looked at some measures of software structure complexity. We can say “this is more complex than this” for a given piece of code or structure. We’ve also looked at two ways to manage it: Abstraction and Modularisation. However, we’ve not really said why complexity entails Risk. So let’s address that now by looking at two analogies, Mass and Technical Debt.
Complexity is Mass
The first way to look at complexity is as Mass : a software project with more complexity has greater mass than one with less complexity. Newton’s Second Law states:
F = ma, ( Force = Mass x Acceleration )
That is, in order to move your project somewhere new, and make it do new things, you need to give it a push, and the more mass it has, the more Force you’ll need to move (accelerate) it.
You could stop here and say that the more lines of code a project contains, the greater its mass. And, that makes sense, because in order to get it to do something new, you’re likely to need to change more lines.
But there is actually some underlying sense in which this is true in the real, physical world too, as discussed in this Veritasium video. To paraphrase:
“Most of your mass you owe due to E=mc², you owe to the fact that your mass is packed with energy, because of the interactions between these quarks and gluon fluctuations in the gluon field… what we think of as ordinarily empty space… that turns out to be the thing that gives us most of our mass.” - Your Mass is NOT From the Higgs Boson, Veritasium
I’m not an expert in physics, at all, and so there is every chance that I am pushing this analogy too hard. But, substituting quarks and gluons for pieces of software we can (in a very handwaving-y way) say that more connected software has more interactions going on, and therefore has more mass than simple software.
If we want to move fast we need simple codebases.
At a basic level, Complexity Risk heavily impacts on Schedule Risk: more complexity means you need more force to get things done, which takes longer.
Technical Debt
The most common way we talk about Complexity Risk in software is as Technical Debt:
“Shipping first time code is like going into debt. A little debt speeds development so long as it is paid back promptly with a rewrite… The danger occurs when the debt is not repaid. Every minute spent on not-quite-right code counts as interest on that debt. Entire engineering organisations can be brought to a stand-still under the debt load of an unconsolidated implementation, object-oriented or otherwise.” - Ward Cunningham, 1992, Wikipedia, Technical Debt
Building a low-complexity first-time solution is often a waste: in the first version, we’re usually interested in reducing Feature RIsk as fast as possible. That is, putting working software in front of users to get feedback. We would rather carry Complexity Risk than take on more attendant Schedule Risk.
So a quick-and-dirty, over-complex implementation mitigates the same Feature Risk and allows you to Meet Reality faster.
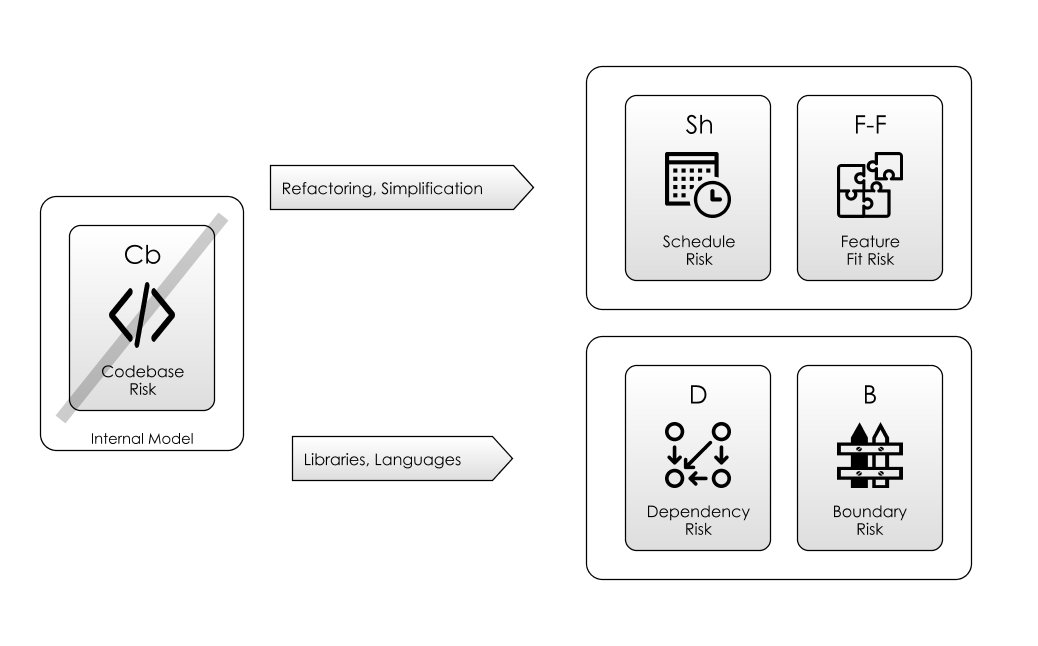
But having mitigated the Feature Risk this way, you are likely exposed to more Complexity Risk than you necessarily need. As the above diagram shows, one of the ways to mitigate Complexity Risk is by Refactoring the software, which means using the tools of abstraction and modularisation.
Kitchen Analogy
It’s often hard to make the case for minimising Technical Debt: it often feels that there are more important priorities, especially when technical debt can be “swept under the carpet” and forgotten about until later. (See Discounting The Future.)
One helpful analogy I have found is to imagine your code-base is a kitchen. After preparing a meal (i.e. delivering the first implementation), you need to tidy up the kitchen. This is just something everyone does as a matter of basic sanitation.
Now of course, you could carry on with the messy kitchen. When tomorrow comes and you need to make another meal, you find yourself needing to wash up saucepans as you go, or working around the mess by using different surfaces to chop on.
It’s not long before someone comes down with food poisoning.
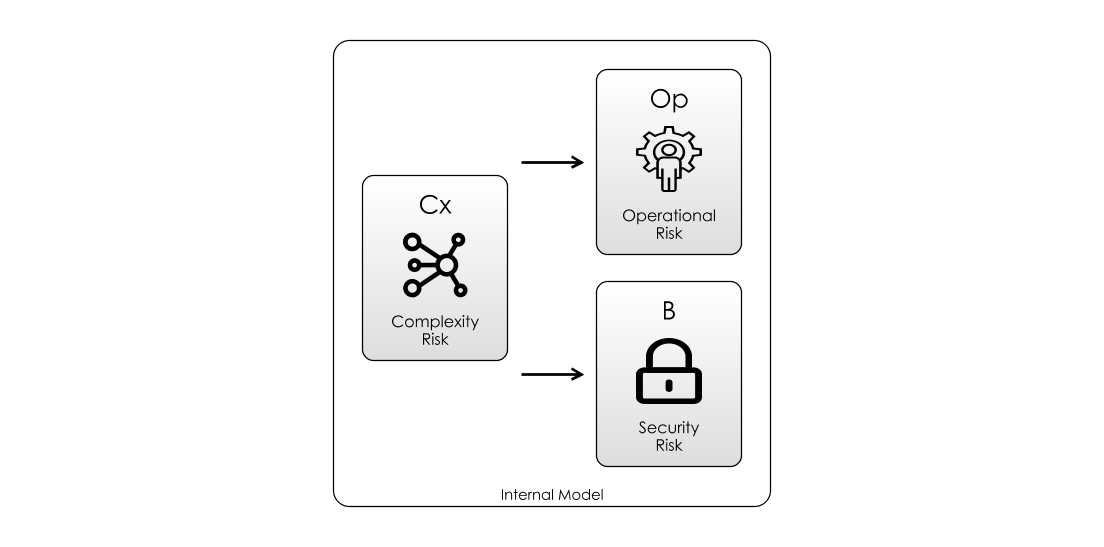
We wouldn’t tolerate this behaviour in a restaurant kitchen, so why put up with it in a software project? This state-of-affairs is illustrated in the above diagram: Complexity Risk can be a cause of Operational Risks and Security Risks.
Feature Creep
In Brooks’ essay “No Silver Bullet - Essence and Accident in Software Engineering”, a distinction is made between:
- Essence: the difficulties inherent in the nature of the software.
- Accident: those difficulties that attend its production but are not inherent. - Fred Brooks, No Silver Bullet
The problem with this definition is that we are accepting features of our software as essential.
Applying Risk-First, if you want to mitigate some Feature Risk then you have to pick up Complexity Risk as a result. But, that’s a choice you get to make.
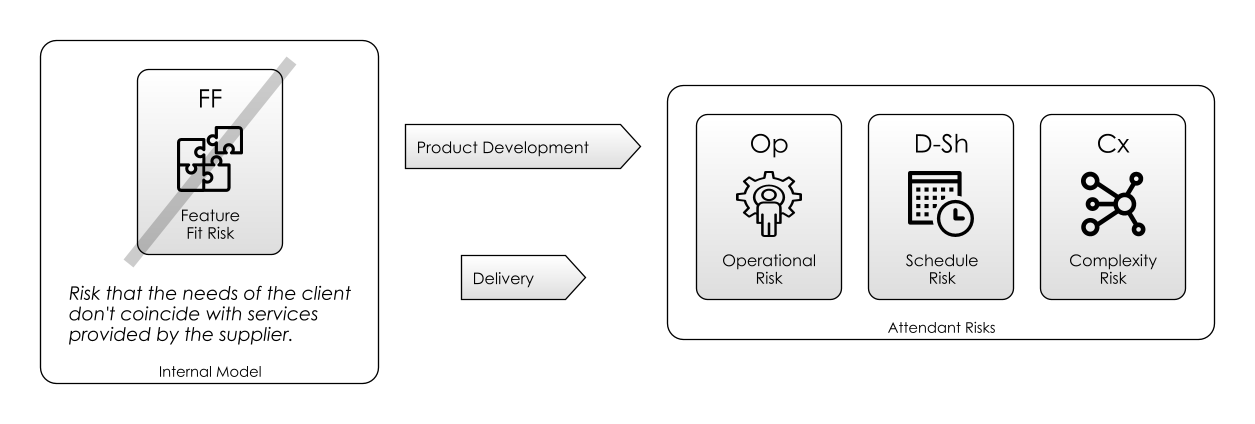
Therefore, Feature Creep (or Gold Plating) is a failure to observe this basic equation: instead of considering this trade off, you’re building every feature possible. This will impact on Complexity Risk.
Sometimes, feature-creep happens because either managers feel they need to keep their staff busy, or the staff decide on their own that they need to keep themselves busy. This is something we’ll return to in Agency Risk.
Dead-End Risk
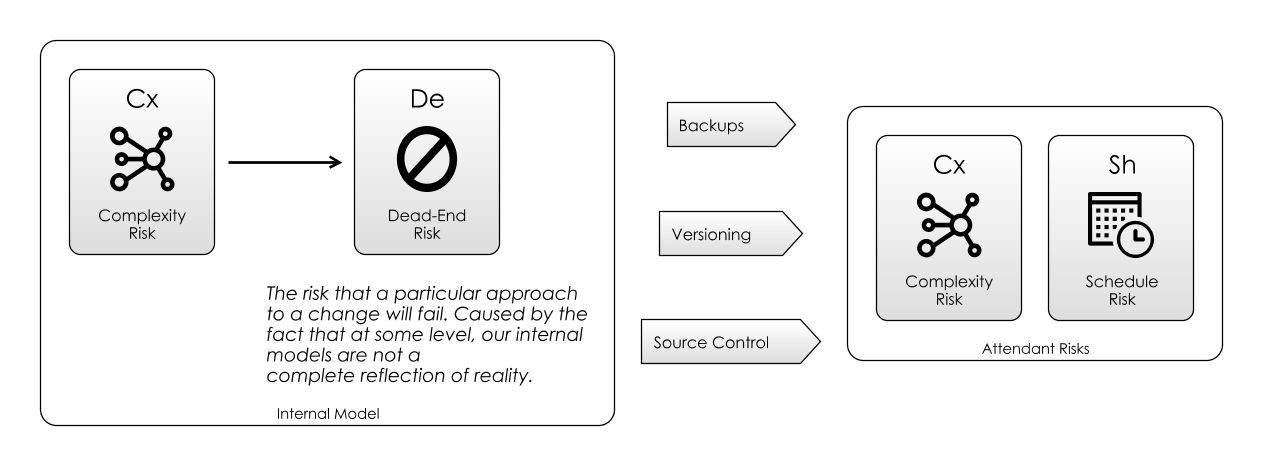
Dead-End Risk is where you take an action that you think is useful, only to find out later that actually, it was a dead-end, and your efforts were wasted. Here, we’ll see that Complexity Risk is a big cause of this (as the above diagram shows).
For example, imagine a complex software system composed of many sub-systems. Let’s say that the Accounting sub-system needed password protection (so you built this). Then the team realised that you needed a way to change the password (so you built that). Then, that you needed to have more than one user of the Accounting system so they would all need passwords (OK, fine).
Finally, the team realises that actually authentication would be something that all the sub-systems would need, and that it had already been implemented more thoroughly by the Approvals sub-system.
At this point, you realise you’re in a Dead End:
- Option 1: Continue. You carry on making minor incremental improvements to the accounting authentication system (carrying the extra Complexity Risk of the duplicated functionality).
- Option 2: Merge. You rip out the accounting authentication system, and merge in the Approvals authentication system, consuming lots of development time in the process, due to the difficulty in migrating users from the old to new way of working. There is Implementation Risk here.
- Option 3: Remove. You start again, trying to take into account both sets of requirements at the same time, again, possibly surfacing new hidden Complexity Risk due to the combined approach. Rewriting code or a whole project can seem like a way to mitigate Complexity Risk, but it usually doesn’t work out too well. As Joel Spolsky says:
There’s a subtle reason that programmers always want to throw away the code and start over. The reason is that they think the old code is a mess. And here is the interesting observation: they are probably wrong. The reason that they think the old code is a mess is because of a cardinal, fundamental law of programming: It’s harder to read code than to write it. - Things You Should Never Do, Part 1, Joel Spolsky
Whichever option you choose, this is a Dead End because with hindsight, it would probably have been better to do authentication in a common way once. But it’s hard to see these dead-ends up-front because of the complexity of the system in front of you.
Sometimes, the path across the Risk Landscape will take you to dead ends, and the only benefit to be gained is experience. No one deliberately chooses a dead end - often you can take an action that doesn’t pay off, but frequently the dead end appears from nowhere: it’s a Hidden Risk. The source of a lot of this hidden risk is the complexity of the risk landscape.
Version Control Systems like Git are a useful mitigation of Dead-End Risk, because using them means that at least you can go back to the point where you made the bad decision and go a different way. Additionally, they provide you with backups against the often inadvertent Dead-End Risk of someone wiping the hard-disk.
Where Complexity Hides
So far, we’ve focused mainly on Codebase Risk, but this isn’t the only place complexity appears in software. We’re going to cover a few of these areas now, but be warned, this is not a complete list by any means:
- Algorithmic (Space and Time) Complexity
- Memory Management
- Protocols / Types
- Concurrency / Mutability
- Networks / Security
- The Environment
Space and Time Complexity
There is a whole branch of complexity theory devoted to how the software runs, namely Big O Complexity.
Once running, an algorithm or data structure will consume space or runtime dependent on its performance characteristics, which may well have an impact on the Operational Risk of the software. Using off-the-shelf data structures and algorithms helps, but you still need to know their performance characteristics.
The Big O Cheat Sheet is a wonderful resource to investigate this further.
Memory Management
Memory Management (and more generally, all resource management in software) is another place where Complexity Risk hides:
“Memory leaks are a common error in programming, especially when using languages that have no built in automatic garbage collection, such as C and C++.” - Memory Leak, Wikipedia
Garbage Collectors (as found in Javascript or Java) offer you the deal that they will mitigate the Complexity Risk of you having to manage your own memory, but in return perhaps give you fewer guarantees about the performance of your software. Again, there are times when you can’t accommodate this Operational Risk, but these are rare and usually only affect a small portion of an entire software-system.
Protocols And Types
As we saw in Communication Risk, whenever two components of a software system need to interact, they have to establish a protocol for doing so. As systems become more complex, and the connectedness increases, it becomes harder to manage the risk around versioning protocols. This becomes especially true when operating beyond the edge of the compiler’s domain.
Although type checking helps mitigate Protocol Risk in the small, when software systems grow large it becomes hard to communicate their intent and keep their degree of connectivity low, and you end up with the Big Ball Of Mud:
“A big ball of mud is a software system that lacks a perceivable architecture. Although undesirable from a software engineering point of view, such systems are common in practice due to business pressures, developer turnover and code entropy. “ - Big Ball Of Mud, Wikipedia
Concurrency / Mutability
Although modern languages include plenty of concurrency primitives (such as the java.util.concurrent libraries), concurrency is still hard to get right.
Race conditions and Deadlocks abound in over-complicated concurrency designs: complexity issues are magnified by concurrency concerns, and are also hard to test and debug.
Recently, languages such as Clojure have introduced persistent collections to alleviate concurrency issues. The basic premise is that any time you want to change the contents of a collection, you get given back a new collection. So, any collection instance is immutable once created. The tradeoff is again speed to mitigate Complexity Risk.
An important lesson here is that choice of language can reduce complexity: and we’ll come back to this in Software Dependency Risk.
Networking / Security
There are plenty of Complexity Risk perils in anything to do with networked code, chief amongst them being error handling and (again) protocol evolution.
In the case of security considerations, exploits thrive on the complexity of your code, and the weaknesses that occur because of it. In particular, Schneier’s Law says, never implement your own cryptographic scheme:
“Anyone, from the most clueless amateur to the best cryptographer, can create an algorithm that he himself can’t break. It’s not even hard. What is hard is creating an algorithm that no one else can break, even after years of analysis.” - Bruce Schneier, 1998
Luckily, most good languages include cryptographic libraries that you can include to mitigate these Complexity Risks from your own code-base.
This is a strong argument for the use of libraries. But, when should you use a library and when should you implement yourself? This is again covered in the section on Software Dependency Risk.
The Environment
The complexity of software tends to reflect the complexity of the environment it runs in, and complex software environments are more difficult to reason about, and more susceptible to Operational Risk and Security-Risk.
In particular, when we talk about the environment, we are talking about the number of dependencies that the software has, and the risks we face when relying on those dependencies.
So the next stop in the tour is a closer look at Dependency Risk.