Risk-First Analysis Framework
Start Here
Home
Contributing
Quick Summary
A Simple Scenario
The Risk Landscape
Discuss
Please star this project in GitHub to be invited to join the Risk First Organisation.
Publications

Click Here For Details
Software Dependency Risk
In this section, we’re going to look specifically at Software dependencies, although many of the concerns we’ll raise here apply equally to all the other types of dependency we outlined in Dependency Risk.
Kolmogorov Complexity: Cheating
In the earlier section on Complexity Risk we tackled Kolmogorov Complexity, and the idea that your codebase had some kind of minimal level of complexity based on the output it was trying to create. This is a neat idea, but in a way, we cheated. Let’s look at how.
We were trying to figure out the shortest (Javascript) program to generate this output:
abcdabcdabcdabcdabcdabcdabcdabcdabcdabcd
And we came up with this:
const ABCD="ABCD"; (11 symbols)
function out() { (7 symbols)
return ABCD.repeat(10) (7 symbols)
} (1 symbol)
Which had 26 symbols in it.
Now, here’s the cheat: the repeat() function was built into Javascript in 2015 in ECMAScript 6.0. If we’d had to program it ourselves, we might have added this:
function repeat(s,n) { (10 symbols)
var a=[]; (7 symbols)
while(a.length<n){ (9 symbols)
a.push(s) (6 symbols)
} (1 symbol)
return a.join(''); (10 symbols)
} (1 symbol)
… which would be an extra 44 symbols (in total 70), and push us completely over the original string encoding of 53 symbols. So, encoding language is important.
Conversely, if ECMAScript 6.0 had introduced a function called abcdRepeater(n) we’d have been able to do this:
function out() { (7 symbols)
return abcdRepeater(10) (6 symbols)
} (1 symbol)
.. and re-encode to 14 symbols. Now, clearly there are some problems with all this:
- Language Matters: the Kolmogorov complexity is dependent on the language, and the features the language has built in.
- Exact Kolmogorov complexity is uncomputable anyway: Since it’s the theoretical minimum program length, it’s a fairly abstract idea, so we shouldn’t get too hung up on this. There is no function to be able to say, “what’s the Kolmogorov complexity of string X”
- What is this new library function we’ve created? Is
abcdRepeatergoing to be part of every Javascript? If so, then we’ve shifted Codebase Risk away from ourselves, but we’ve pushed Communication Risk and Dependency Risk onto every other user of Javascript. (Why these? BecauseabcdRepeaterwill be clogging up the documentation and other people will rely on it to function correctly.) - Are there equivalent functions for every single other string? If so, then compilation is no longer a tractable problem because now we have a massive library of different
XXXRepeaterfunctions to compile against to see if it is… So, what we lose in Codebase Risk we gain in Dependency Risk. - Language design, then, is about ergonomics: After you have passed the relatively low bar of providing Turing Completeness, the key is to provide useful features that enable problems to be solved, without over-burdening the user with features they don’t need. And in fact, all software is about this.
Ergonomics Examined
Have a look at some physical tools, like a hammer, or spanner. To look at them, they are probably simple objects, obvious, strong and dependable. Their entire behaviour is encapsulated in their form. Now, if you have a drill or sander to hand, look at the design of this too. If it’s well-designed, then from the outside it is simple, perhaps with only one or two controls. Inside, it is complex and contains a motor, perhaps a transformer, and is maybe made of a hundred different components.
But outside, the form is simple, and designed for humans to use. This is ergonomics:
“Human factors and ergonomics (commonly referred to as Human Factors), is the application of psychological and physiological principles to the (engineering and) design of products, processes, and systems. The goal of human factors is to reduce human error, increase productivity, and enhance safety and comfort with a specific focus on the interaction between the human and the thing of interest.” - Human Factors and Ergonomics, Wikipedia
Protocols and Ergonomics
The interface of a tool is the part we touch and interact with, via its protocol. By striving for an ergonomic sweet spot, the protocol reduces Communication Risk.
The interface of a system expands when you ask it to do a wide variety of things. An easy-to-use drill does one thing well: it turns drill-bits at useful levels of torque for drilling holes and sinking screws. But if you wanted it to also operate as a lathe, a sander or a strimmer (all basically mechanical things going round) you would have to sacrifice the conceptual integrity for a more complex protocol, probably including adapters, extensions, handles and so on.
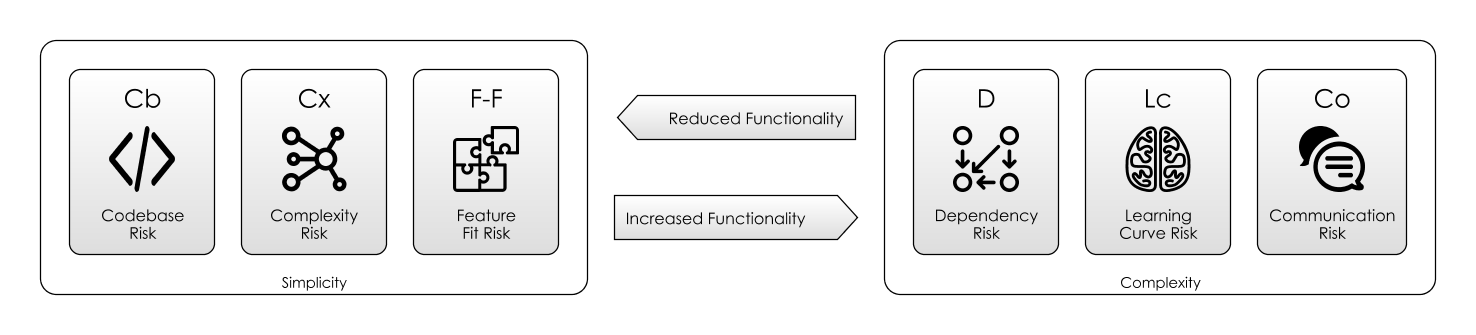
So, we now have split complexity into two:
- The inner complexity of the tool (how it works internally, its own internal complexity).
- The complexity of the instructions that we need to write to make the tool work, the protocol complexity, which will be a function of the complexity of the tool itself..
Software Tools
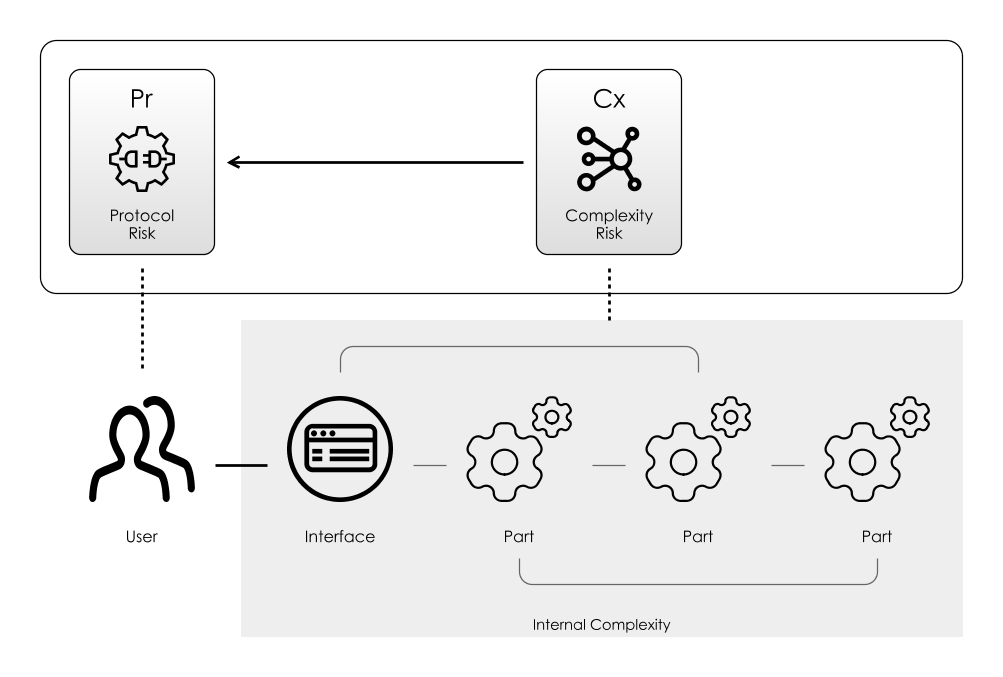
In the same way as with a hand-tool, the bulk of the complexity of a software tool is hidden behind its interface. But, the more complex the purpose of the tool, the more complex the interface will be.
Software is not constrained by physical ergonomics in the same way as a tool is. But ideally, it should have conceptual ergonomics: ideally, complexity is hidden away from the user behind the User Interface. This is the familiar concept of Abstraction we’ve already looked at. As we saw in Communication Risk, when we use a new protocol, we face Learning Curve Risk. To minimise this, we should apply the Principal Of Least Astonishment when designing protocols:
- The abstractions should map easily to how the user expects the tool to work. For example, I expect the trigger on a drill to start the drill turning.
- The abstractions should leverage existing idioms and knowledge. In a new car, I expect to know what the symbols on the dashboard mean, because I’ve driven other cars.
- The abstractions provide me with only the functions I need. Because everything else is confusing and gets in the way.
Types Of Software Dependencies
There are lots of ways you can depend on software. Here though, we’re going to focus on just three main types:
- Code Your Own: write some code ourselves to meet the dependency.
- Software Libraries: importing code from the Internet, and using it in our project. Often, libraries are Open Source (this is what we’ll consider here).
- Software-as-a-Service (SaaS): calling a service on the Internet, (probably via
http) This is often known as SaaS, or Software as a Service.
All 3 approaches involve a different risk-profile. Let’s look at each in turn, from the perspective of which risks get mitigated, and which risks are accentuated.
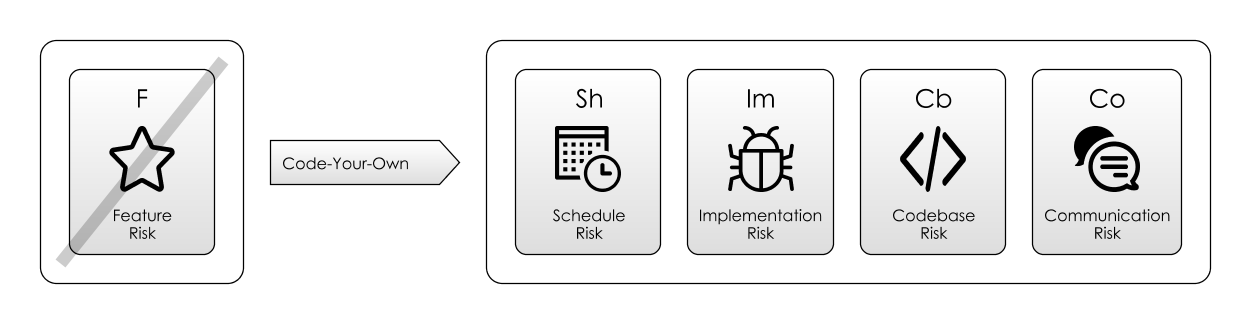
1. Code Your Own
Way before the Internet, this was the only game in town. Tool support was very thin-on-the-ground. Algorithms could be distributed as code snippets in magazines which could be transcribed and run, and added to your program. This spirit lives on somewhat in StackOverflow and JSFiddle, where you are expected to “adopt” others’ code into your own project. Code-your-own is still the best option if you have highly bespoke requirements, or are dealing with unusual environmental contexts.
One of the hidden risks of embarking on a code-your-own approach is that the features you need are not apparent from the outset. What might appear to be a trivial implementation of some piece of functionality can often turn into its own industry as more and more hidden Feature Risk is uncovered. For example, as we discussed in our earlier treatment of Dead-End Risk, building log-in screens seemed like a good idea. However, this gets out-of-hand fast when you need:
- A password reset screen
- To email the reset links to the user
- An email verification screen
- A lost account screen
- Reminders to complete the sign up process
- … and so on.
Unwritten Software
Sometimes, you will pick up Dependency Risk from unwritten software. This commonly happens when work is divided amongst team members, or teams.
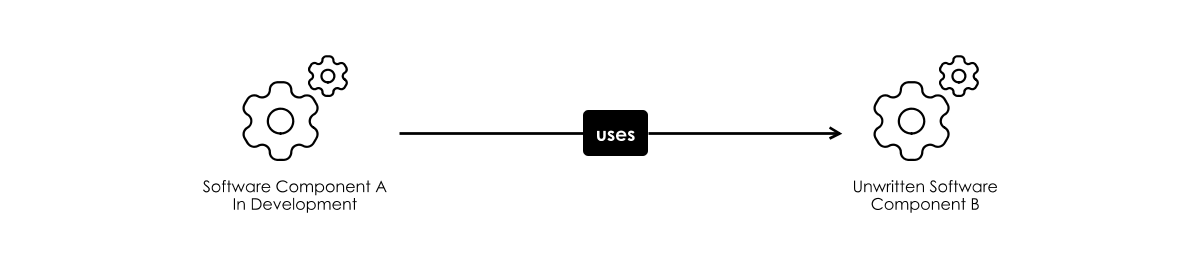
If a component A of our project depends on B for some kind of processing, you might not be able to complete A before writing B. This makes scheduling the project harder, and if component A is a risky part of the project, then the chances are you’ll want to mitigate risk there first.
But it also hugely increases Communication Risk because now you’re being asked to communicate with a dependency that doesn’t really exist yet, let alone have any documentation.
There are a couple of ways to do this:
-
Standards: if component B is a database, a queue, mail gateway or something else with a standard interface, then you’re in luck. Write A to those standards, and find a cheap, simple implementation to test with. This gives you time to sort out exactly what implementation of B you’re going for. This is not a great long-term solution, because obviously, you’re not using the real dependency- you might get surprised when the behaviour of the real component is subtly different. But it can reduce Schedule Risk in the short-term.
-
Coding To Interfaces: if standards aren’t an option, but the surface area of B that A uses is quite small and obvious, you can write a small interface for it, and work behind that, using a Mock for B while you’re waiting for finished component. Write the interface to cover only what A needs, rather than everything that B does in order to minimise the risk of Leaky Abstractions.

Conway’s Law
Due to channel bandwidth limitations, if the dependency is being written by another person, another team or in another country, Communication Risk piles up. When this happens, you will want to minimise the interface complexity as much as possible, since the more complex the interface, the worse the Communication Risk will be. The tendency then is to make the interfaces between teams or people as simple as possible, modularising along these organisational boundaries.
In essence, this is Conway’s Law:
“organisations which design systems … are constrained to produce designs which are copies of the communication structures of these organisations.” — M. Conway, Conway’s Law
2. Software Libraries
By choosing a particular software library, we are making a move on the Risk Landscape in the hope of moving to place with more favourable risks. Typically, using library code offers a Schedule Risk and Complexity Risk Silver Bullet - a high-speed route over the risk landscape to somewhere nearer where we want to be. But, in return we expect to pick up:
- Communication Risk: because we now have to learn how to communicate with this new dependency.
- Boundary Risk: - because now are limited to using the functionality provided by this dependency. We have chosen it over alternatives and changing to something else would be more work and therefore costly.
But, it’s quite possible that we could wind up in a worse place than we started out, by using a library that’s out-of-date, riddled with bugs or badly supported. i.e. Full of new, hidden Feature Risk.
It’s really easy to make bad decisions about which tools to use because the tools don’t (generally) advertise their deficiencies. After all, they don’t generally know how you will want to use them.
Software Libraries - Attendant Risks
Currently, choosing software dependencies looks like a “bounded rationality”-type process:
“Bounded rationality is the idea that when individuals make decisions, their rationality is limited by the tractability of the decision problem, the cognitive limitations of their minds, and the time available to make the decision. “ - Bounded Rationality, Wikipedia
Unfortunately, we know that most decisions don’t really get made this way. We have things like Confirmation Bias (looking for evidence to support a decision you’ve already made) and Cognitive Inertia (ignoring evidence that would require you to change your mind) to contend with.
But, leaving that aside, let’s try to build a model of what this decision making process should involve. Luckily, other authors have already considered the problem of choosing good software libraries, so let’s start there.
In the table below, I am summarising three different sources (linked at the end of the section), which give descriptions of which factors to look for when choosing open-source libraries.

The diagram above summarises the risks raised in some of the literature. Here are some take-aways:
- Feature Risk is a big concern: How can you be sure that the project will do what you want it to do ahead of schedule? Will it contain bugs or missing features? By looking at factors like release frequency and size of the community you get a good feel for this which is difficult to fake.
- Boundary Risk is also very important: You are going to have to live with your choices for the duration of the project, so it’s worth spending the effort to either ensure that you’re not going to regret the decision, or that you can change direction later.
- Third is Communication Risk: how well does the project deal with its users? If a project is “famous”, then it has communicated its usefulness to a wide, appreciative audience. Avoiding Communication Risk is also a good reason to pick tools you are already familiar with.

Sources
sd1: Defending your code against dependency problemssd2: How to choose an open source librarysd3: Open Source - To use or not to use
Complexity Risk?
One thing that none of the sources in the table consider (at least from the outset) is the Complexity Risk of using a solution:
- Does it drag in lots of extra dependencies that seem unnecessary for the job in hand? If so, you could end up in Dependency Hell, with multiple, conflicting versions of libraries in the project.
- Do you already have a dependency providing this functionality? So many times, I’ve worked on projects that import a new dependency when some existing (perhaps transitive) dependency has already brought in the functionality. For example, there are plenty of libraries for JSON marshaling, but if I’m also using a web framework the chances are it already has a dependency on one already.
- Does it contain lots of functionality that isn’t relevant to the task you want it to accomplish? e.g. Using Java when a shell script would do (on a non-Java project)
Sometimes, the amount of complexity goes up when you use a dependency for good reason. For example, in Java, you can use Java Database Connectivity (JDBC) to interface with various types of database. Spring Framework (a popular Java library) provides a thing called a JDBCTemplate. This actually makes your code more complex, and can prove very difficult to debug. However, it prevents some security issues, handles resource disposal and makes database access more efficient. None of those are essential to interfacing with the database, but not using them is Technical Debt that can bite you later on.
To give an extreme example of this, I once worked on an application which used Hazlecast, an in-memory distributed database, to cache log-in session tokens for a 3rd party data-source. But, the app is only used once every month, and session IDs can be obtained in milliseconds. So… why cache them? Although Hazlecast is an excellent choice for in-memory caching across multiple JVMs, it is a complex piece of software (after all, it does lots of stuff). Using it introduced extra dependency risk, cache invalidation risks, networking risks, synchronisation risks and so on, for actually no benefit at all… Unless, it’s about CV Building. (See Agency Risk.)
3. Software-as-a-Service
Businesses opt for Software-as-a-Service (SaaS) because:
- It promises to vastly reduce the Complexity Risk they face in their organisations. e.g. managing the software or making changes to it.
- Payment is usually based on usage, mitigating Funding Risk. e.g. Instead of having to pay up-front for a license, and hire in-house software administrators, they can leave this function to the experts.
- Potentially, you out-source the Operational Risk to a third party. e.g. ensuring availability, making sure data is secure and so on.
SaaS is now a very convenient way to provide commercial software. Popular examples of SaaS might be SalesForce, or GMail. Both of which follow the commonly-used Freemium model, where the basic service is provided free, but upgrading to a paid account gives extra benefits.

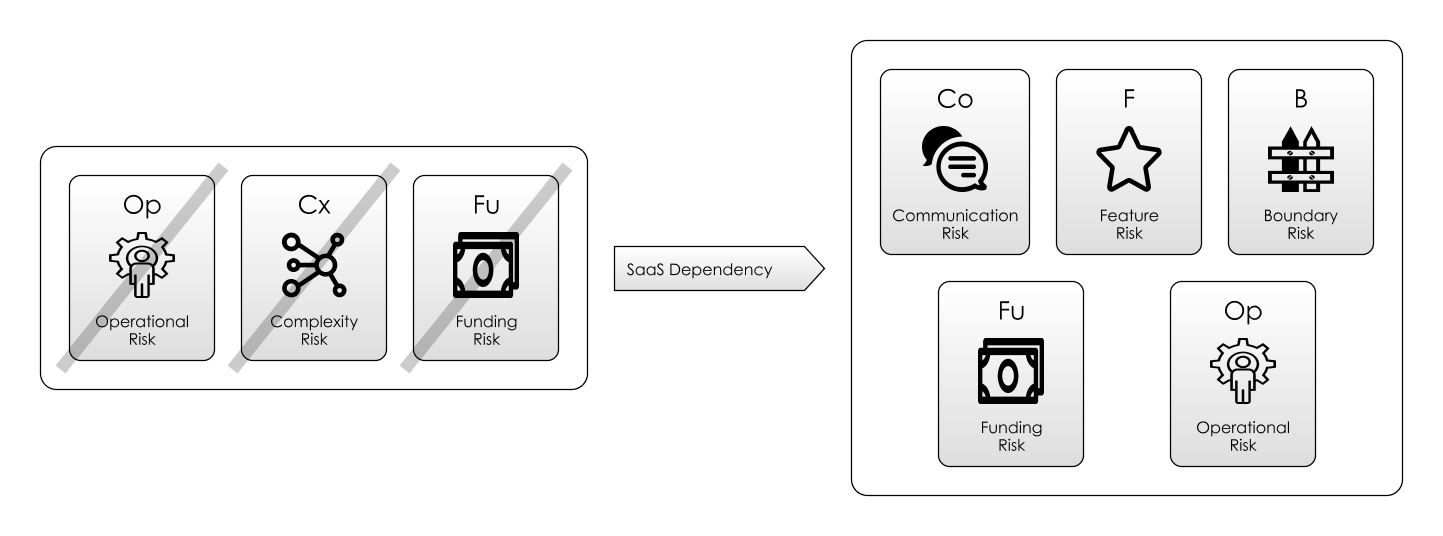
The diagram above summarises the risks raised in some of the available literature. Some take-aways:
- Clearly, Operational Risk is now a big concern. By depending on a third-party organisation you are tying yourself to its success or failure in a much bigger way than just by using a piece of open-source software. What happens to data security, both in the data centre and over the Internet? Although you might choose a SaaS solution to mitigate internal Operational Risk, you might just be “throwing it over the wall” to a third party, who might do a worse job.
- With Feature Risk you now have to contend with the fact that the software will be upgraded outside your control, and you may have limited control over which features get added or changed.
- Boundary Risk is a also a different proposition: you are tied to the software provider by a contract. If the service changes in the future, or isn’t to your liking, you can’t simply fork the code (like you could with an open source project).
Sources
A Matrix of Options
We’ve looked at just 3 different ways of providing a software dependency: Code-Your-Own, Libraries and SaaS.
But these are not the only ways to do it, and there’s clearly no one right way. Although here we have looked just at “Commercial SaaS” and “Free Open Source”, in reality, these are just points in a two-dimensional space involving Pricing and Hosting.
Let’s expand this view slightly and look at where different pieces of software sit on these axes:

- Where there is value in the Network Effect:, it’s often a sign that the software will be free, or open source: programming languages and Linux are the obvious examples of this. Bugs are easier to find when there are lots of eyes looking, and learning the skill to use the software has less Boundary Risk if you know you’ll be able to use it at any point in the future.
- At the other end of the spectrum, clients will happily pay for software if it clearly reduces Operational Risk. Take Amazon Web Services (AWS). The essential trade here is that you substitute the complexity of hosting and maintaining various pieces of hardware, in exchange for metered payments (Funding Risk for you). Since the AWS interfaces are specific to Amazon, there is significant Boundary Risk in choosing this option.
- In the middle there are lots of substitute options and therefore high competition. Because of this, prices are pushed towards zero, and and therefore often advertising is used to monetarise the product. Angry Birds is a classic example: initially, it had demo and paid versions, however Rovio discovered there was much more money to be made through advertising than from the paid-for app.
Software Dependencies as Features
So far, we’ve looked at different approaches to software dependencies, and the risk profiles they present. But the category is less important than the specifics: we are choosing specific tools for specific tasks. Software Dependencies allows us to construct dependency networks to give us all kinds of features and mitigate all kinds of risk. That is, the features we are looking for in a dependency are to mitigate some kind of risk.
For example, I might start using WhatsApp because I want to be able to send my friends photos and text messages. However, it’s likely that those same features allow us to mitigate Coordination Risk when we’re next trying to meet up.
Let’s look at some:
| Risk | Examples of Software Mitigating That Risk |
|---|---|
| Coordination Risk | Calendar tools, Bug Tracking, Distributed Databases |
| Map-And-Territory-Risk | The Internet, generally. Excel, Google, “Big Data”, Reporting tools |
| Schedule-Risk | Planning Software, Project Management Software |
| Communication-Risk | Email, Chat tools, CRM tools like SalesForce, Forums, Twitter, Protocols |
| Process-Risk | Reporting tools, online forms, process tracking tools |
| Agency-Risk | Auditing tools, transaction logs, Time-Sheet software, HR Software |
| Operational-Risk | Support tools like ZenDesk, Grafana, InfluxDB, Geneos, Security Tools |
| Feature-Risk | Every piece of software you use! |
Choice
Choosing dependencies can be extremely difficult. As we discussed above, the usefulness of any tool depends on its fit for purpose, its ergonomics within a given context. It’s all too easy to pick a good tool for the wrong job:
“I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.” - Abraham Maslow, Toward a Psychology of Being
Having chosen a dependency, whether or not you end up in a more favourable position risk-wise is going to depend heavily on the quality of the execution and the skill of the implementor. With software dependencies, we often have to live with the decisions we make for a long time. In my experience, given the Boundary Risks associated with getting this wrong, not enough time is spent really thinking about this in advance.
Let’s take a closer look at this problem in the next section, Boundary Risk.